소개
NazareDB는 차세대 데이터베이스 솔루션으로서, 고성능 저비용 실시간 빅데이터 처리를 위해 설계되었습니다. Nazare 데이터 플랫폼과의 결합을 통해 BI 및 AI 어플리케이션에 강력한 데이터 인프라를 제공하며, 데이터 관리의 복잡성과 비용 문제를 해결합��니다. 제조 산업에서 IIoT 기술과 빅데이터를 접목해 예지보전 및 공정 개선에 활용하려는 기업들에게 NazareDB는 기존 솔루션들의 한계를 넘어서는 최적의 해결책을 제공합니다.
제조 산업을 위한 빅데이터 문제 정의 및 해결
제조 산업의 데이터는 제조 공정, 제어 시스템, 센서, 제어 장치 등을 포함하며, 실시간 데이터 처리와 응답성이 중요한 특징을 가지고 있습니다. 대부분 시계열 데이터로 구성되어 있으며, 실시간으로 생성되고 처리되어야 합니다.
또한 제조사 별 파편화된 산업용 프로토콜(e.g. PLC, MODBUS, OPC-UA 등)로 인해 같은 타입의 설비라 할지라도 데이터 소스 별로 생성되는 데이터 들은 모두 다른 형태로 생성됩니다.
따라서 OT(Operation Technology) 기술에서 생성된 데이터는 데이터 소스 별로 별도의 파이프라인과 별도의 빅데이터 테이블로 처리되어야 합니다.
제조 산업의 데이터들은 대부분 아날라고 시계열 데이터로 구성되어 있고 시계열 데이터를 처리하는 데 최적화된 데이터베이스 솔루션이 필요합니다. 또한 아날로그 데이터 기반이기에 촘촘하게(초당 수십 ~ 수 백개 이상의 레코드) 데이터가 수집될 수록 이후의 데이터 분석이나 AI 활용에 유리하기 때문에 대용량 데이터 처리가 필요합니다.
그리고 제조 장비는 장애 발생시 큰 손실을 가�져오기 때문에 예지보전이 중요합니다. 이를 위해 실시간 데이터 분석을 위한 데이터 솔루션이 필요합니다.
이는 기존의 IT(Information Technology) 기술에서 생성되는 빅 데이터와 유사하면서도 매우 다른 특성을 가지기 때문에 이에 적합한 전용 파이프 라인과 데이터베이스 솔루션이 필요합니다.
이 문제를 해결하기 위해 NazareDB는 고성능 실시간 데이터 처리와 분석을 위한 새로운 접근 방식을 제공합니다.
문제 정의
- OT와 IT 간 데이터 특성 차이가 존재
- 아날로그 시계열 vs IT의 데이터는 디지털 이벤트 데이터
- 데이터 소스 별 별도의 파이프라인 vs 하나의 파이프라인으로 수집
- 데이터 소스 별 다른 스키마 테이블로 수집 vs 하나의 빅 테이블로 수집
- 실시간 데이터 처리 및 예지보전 vs 배치 처리 및 분석
- 기존 데이터 웨어하우스 솔루션 들(e.g. RDBMS, NoSQL, Key-Value DB, TimeseriesDB 등)은 빅데이터 저장 및 처리에 부적합
- 빅데이터를 저장하는게 애초에 불가능하거나 저장 가능하더라도 성능 저하가 발생
- OLTP 기반 기술을 사용하기 때문에 빅데이터 처리에 적합하지 않음
- 기존 빅데이터 솔루션 들(e.g. Hadoop, Hive, Spark, Trino, 등)은 복잡하고 많은 인프라 투자가 필요
- JVM 기반으로 많은 메모리와 GC 오베헤드 등이 발생하고 태생적으로 컨테이너 환경에 적합하지 않음
- 운영시 많은 서비스 설치 및 관리가 �필요함 (e.g. 분산 스트리밍/배치 파이프라인, 분산 메시지 브로커, 분산 스토리지, 분산 쿼리 엔진 등)
- 대용량 배치 처리에 주로 특화되어 있어 지연 시간이 길고 실시간 데이터 처리에 적합하지 않음
- OLAP 기반 기술을 사용하지만 row 방식과 column 방식이 혼용되고 있어 serialization/deserialization 오버헤드가 발생
- BI(Business Intelligence)를 위해서는 데이터 웨어하우스를 사용하고 AI(Artificial Intelligence)를 위해서는 데이터 레이크로 분리되어 운영
해결 방안
NazareDB는 이러한 문제를 극복하기 위해 안전한 메모리 관리와 고성능을 가진 Rust 프로그래밍 언어로 개발되었으며, OLAP에 적합한 Apache Arrow 포맷을 기반으로 한 Apache Datafusion 쿼리 엔진을 사용합니다. 이러한 기술적 접근 방식은 다음과 같은 해결책을 제공합니다:
- 고성능 실시간 데이터 처리: Rust의 낮은 메모리 사용 및 고성능은 기존 솔루션들의 문제를 해결하며, 온프레미스 서버 단 1대로도 고성능 빅데이터 데이터베이스 기능을 제공합니다.
- 컨테이너 환경에 최적화: Rust의 메모리 관리는 JVM의 회수되지 않는 메모리 관리 보다 효울적이며 특히 swap을 적극적으로 활용 가능하며 여러 컨테이너가 동시에 실행되는 환경에서 더욱 효율적으로 동작합니다.
- 효율적인 FDAP 아키텍쳐: Flight, DataFusion, Arrow, and Parquet (FDAP) 의 오픈소스를 적극 활용하여 빅데이터 처리에 최적화된 아키텍처를 제공하면서 효율적인 개발 및 운영을 가능하게 합니다.
- 버티컬 최적화: 스토리지와 컴퓨팅 분리 및 일관된 메모리 포맷 사용 등 하위부터 상위 컴포넌트까지 최적화된 소프트웨어를 활용하여 최적화된 성능을 제공합니다.
제품 아키텍처
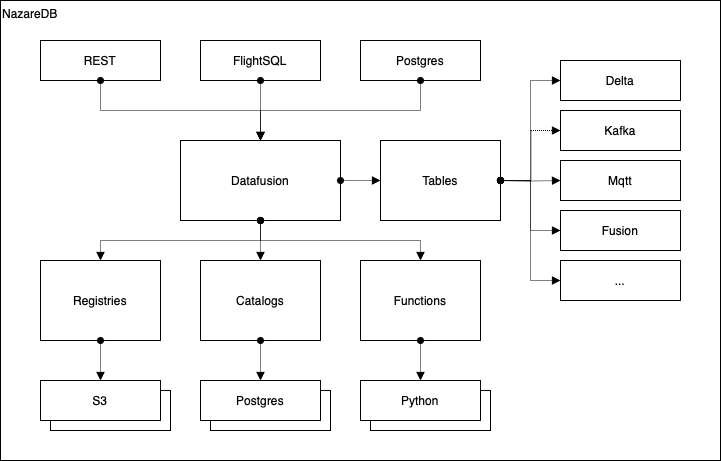
NazareDB의 아키텍처는 다음과 같은 주요 컴포넌트로 구성됩니다:
Client 인터페이스 컴포넌트
- Rest API Interface: 모든 플랫폼에서 사용가능한 표준적인 Rest 프로토콜을 통해 외부 시스템이나 파트너와 데이터를 안전하게 공유할 수 있는 REST API를 제공합니다.
- Arrow Flight SQL Interface: Arrow 인메모리를 기반으로 한 컬럼 형식을 사용하는 ADBC 프로토콜을 통해 데이터 변환이 필요없는 고성능의 OLTP 접근 인터페이스를 제공합니다.
- PostgreSQL Interface: JDBC 및 DB-API 등과 같은 전통적인 표준 인터페이스를 사용하는 Legacy 시스템과의 호환성을 위해 PostgreSQL 프로토콜을 지원합니다.
Transform 인터페이스 컴포넌트
- Delta, Kafka, MQTT, Fusion 등의 외부 시스템에 데이터를 적재하는 컴포넌트입니다.
Core 컴포넌트
-
DataFusion: NazareDB는 Apache Arrow DataFusion 오픈소스 쿼리 엔진을 기반으로 동작합니다. 안정적으로 메모리를 관리하는 Rust 언어를 기반으로 Apache Arrow 인메모리 형식을 사용하고 매우 빠르면서 확장 가능한 고품질의 데이터 중심 시스템의 쿼리 엔진을 구축하고 있습니다. DataFusion은 SQL 및 데이터 프레임 API 및 뛰어난 성능을 가지며 CSV, Parquet, JSON 및 Avro 등의 다양한 포맷을 기본 지원하며, 광범위한 사용자 정의 및 훌륭한 커뮤니티를 제공합니다.
-
Tables: 데이터를 테이블 단위로 관리하고 컴포넌트입니다.
Storage 및 Metadata 컴포넌트
- Registries: S3와 같은 object storage 를 저장소로 사용하며, 데이터 레이크를 통해 저장된 데이터를 관리하는 컴포넌트입니다.
- Catalogs: PostgreSQL과 같은 데이터베이스를 메타데이터 관리에 사용하는 컴포넌트입니다.
- Functions: 사용자 정의 함수(UDF)를 관리하는 컴포넌트입니다.
주요 기능
NazareDB는 현대적인 FDAP 아키텍처를 기반으로 개발된, 특히 빅데이터 처리에 강점을 가지는 고성능 빅데이터 데이터베이스 솔루션입니다. 기존의 빅데이터 기반 데이터 소프트웨어 들의 한계를 극복하고 특히 IIoT(Industrial Internet of Things) 분야에서 필요로 하는 실시간성과 빠른 응답성을 매우 적은 비용으로 제공함으로써 차별화됩니다.
실시간 데이터 처리와 분석
NazareDB는 실시간 데이터 스트림의 효율적인 처리와 분석을 지원함으로써, 사용자가 대량의 센서 데이터로부터 신속하게 인사이트를 도출할 수 있도록 돕습니다. 또한 수집된 데이터를 바탕으로 실시간 분석을 수행하는 데 중점을 두며, 이는 IIoT 환경에서 발생하는 다양한 데이터 스트림을 적시에 관리하고 처리하는데 이상적인 기능을 제공합니다.
저비용 운영
스토리지와 컴퓨팅의 분리를 통해 NazareDB는 저비용의 효율적인 데이터 관리를 가능하게 합니다. 특�히 클라우드 환경에서도 최적화된 운영이 가능합니다.
고성능 쿼리 엔진
고도로 최적화된 쿼리 엔진을 통해 NazareDB는 복잡한 데이터 쿼리에 대해 매우 빠른 응답 시간을 제공합니다. 이는 시간에 민감한 IIoT 어플리케이션에서 큰 이점을 제공하며, 사용자는 지연 시간을 거의 경험하지 않습니다.
고도의 확장성
NazareDB는 데이터의 양이 급격히 증가하는 빅데이터 환경에서도 안정적인 성능을 유지합니다. 수평적 및 수직적 확장을 모두 지원하여, 대규모 IIoT 시스템에서 발생하는 방대한 양의 데이터를 효과적으로 처리할 수 있습니다.
Lakehouse 아키텍처의 채택
NazareDB는 구조화되지 않은 빅데이터와 구조화된 데이터를 하나의 플랫폼에서 효율적으로 관리하고 분석할 수 있는 Lakehouse 아키텍처를 채택하고 있습니다. 이는 광범위한 데이터를 효율적으로 관리하고 분석할 수 있도록 돕습니다.
다양한 프로토콜 지원
NazareDB는 실시간 어플리케이션을 위한 REST API, OLAP에 최적화된 Columnar 기반의 고성능 ADBC (Arrow Flight SQL) 프로토콜, 그리고 PostgreSQL와 같은 기존 RDBMS 호환 프로토콜을 지원합니다. 이를 통해 다양한 어플리케이션과 서비스에서 NazareDB의 데이터를 활용할 수 있습니다.
다양한 스토리지 타입 지원
- 클라우드 스토리지 지원: AWS S3, Azure Blob Storage, Google Cloud Storage 등 주요 클라우드 스토리지 서비스와의 통합을 지원합니다.
- 온프레미스 스토리지 지원: Ceph, SeaweedFS, MinIO와 같은 분산 파일 시스템 및 객체 스토리지 솔루션을 지원합니다.
클라우드 및 온프레미스 지원
클라우드 환경과 온프레미스 환경 모두에서의 설치와 운영을 지원합니다. 이는 기업이 비즈니스 요구사항과 인프라 전략에 맞게 데이터베이스 솔루션을 선택할 수 있게 해주며 최대한의 유연성을 제공합니다.
주요 기반 오픈소스
- Delta Lake: Apache License 2.0 - Delta Lake은 ACID 트랜잭션을 Apache Spark™ 및 빅데이터 작업에 제공하는 오픈소스 저장소 계층입니다. Delta Lake
- Apache Arrow DataFusion: Apache License 2.0 - Apache Arrow DataFusion은 메모리 내 데이터 처리를 위한 효율적인 실행 계획 및 쿼리 엔진을 제공하는 오픈소스 프로젝트입니다. Apache DataFusion
- Apache Arrow: Apache License 2.0 - Apache Arrow는 다양한 프로그래밍 언어 및 프레임워크 간에 효율적인 데이터 교환을 위한 표준화된 컬럼 기반 메모리 포맷입니다. Apache Arrow
- Apache Parquet: Apache License 2.0 - Apache Parquet은 컬럼 기반의 데이터 저장 포맷으로, 효율적인 데이터 압축 및 인코딩 스키마를 제공합니다. Apache Parquet